Problem: Implicit parallelism in array languages
Over the past several weeks, I have been thinking about this problem: if we have a programming language where the only permissible data type is an array, can we implicitly parallelize that? The idea of implicit parallelism, as I understand it, is that the compiler automatically creates threads and maps those to the program without the programmer specifying it.
This can become an important problem because of the current trends in processor hardware. The fact is that in the last decade, the processor industry has increased the processor speed by adding more processing cores to their chips. So a language that can better exploit this parallelism will be faster in execution time, all other things being equal.
My hunch is array languages would be more amenable to implicit parallelism because of their declarative nature. Now, I don’t know why it should be true. I don’t have any theory for this assertion. I am thinking around the fact that SQL is very parallelizable and it may be precisely because SQL is declarative. In the same vein, it could be profitable to look at relational database optimizers to see if we can apply the same ideas to array languages.
These ideas may have applications in Machine Learning and Computer Vision. I believe this because a lot of problems in these areas involve manipulating matrices. So parallel matrix algorithms could serve as evaluation benchmarks for this language. The other application area where I think we can evaluate this language is the parallel traversals of undirected graphs when they are represented as adjacency lists.
The pictures that come to my mind when I think about these things look like these:
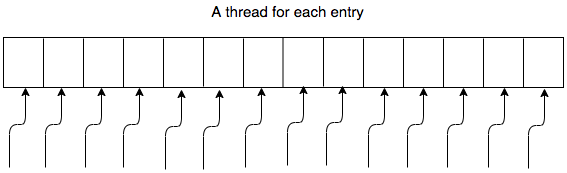
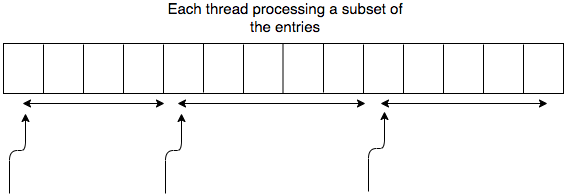
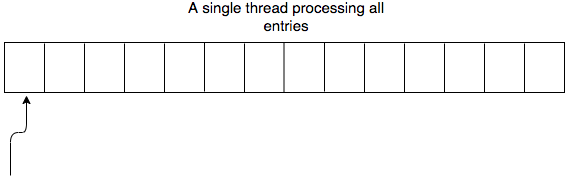
The thing is we can modify the above approach to support hash tables. It may or may not be more challenging than arrays.
Another next step of this can be embedding these techniques in more general purpose languages. Broadly, this could take a form of a compiler making these parallelism decisions whenever it encounters a data structure that can be parallelized.
I am thinking of approaching this problem like this. There is going to be a parser frontend and an optimizer backend. I am ignoring the code generation part for now. Both of these parts can be implemented together. The parser part is more like a typical compiler and the optimizer part is more like a multithreaded program using a set of locks. The optimizer part I feel is going to be influenced by how relational databases are implemented.

In the coming weeks, I will be working more on these ideas and writing about them as the project progresses